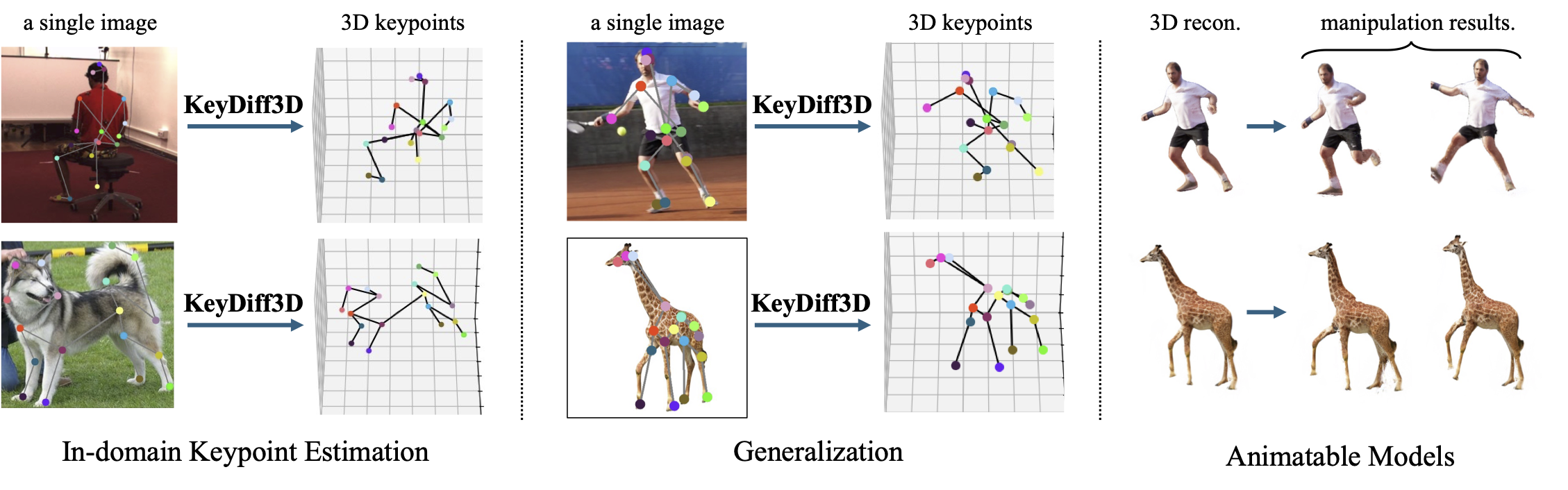
Most existing 3D keypoint estimation methods rely on manual annotations or calibrated multi-view images, both of which are expensive to collect. This paper introduces KeyDiff3D, a framework that can accurately predict 3D keypoints from a single image, thus eliminating the need for such expensive data acquisitions. To achieve this, we leverage powerful geometric priors embedded in a pretrained multi-view diffusion model. In our framework, the diffusion model generates multi-view images from a single image, serving as supervision signals to provide 3D geometric cues to our model. We also introduce a 3D feature extractor that transforms implicit 3D priors embedded in the diffusion features into explicit 3D feature volumes. Beyond accurate keypoint estimation, we further introduce a pipeline that enables manipulation of 3D objects generated by the diffusion model. Experimental results on diverse datasets, including Human3.6M, CUB-200-2011, Stanford Dogs, and several in-the-wild and out-of-domain inputs, highlight the effectiveness of our method in terms of accuracy, generalization, and its ability to enable manipulation of 3D objects generated by the diffusion model from a single image.
From a single image, (1) a pretrained multi-view diffusion model provides novel views and multi-view features, (2) which are aggregated and lifted into a 3D feature volume for keypoint prediction, and (3) the predicted 3D keypoints are projected to the generated views to provide structural cues for self-supervised reconstruction.
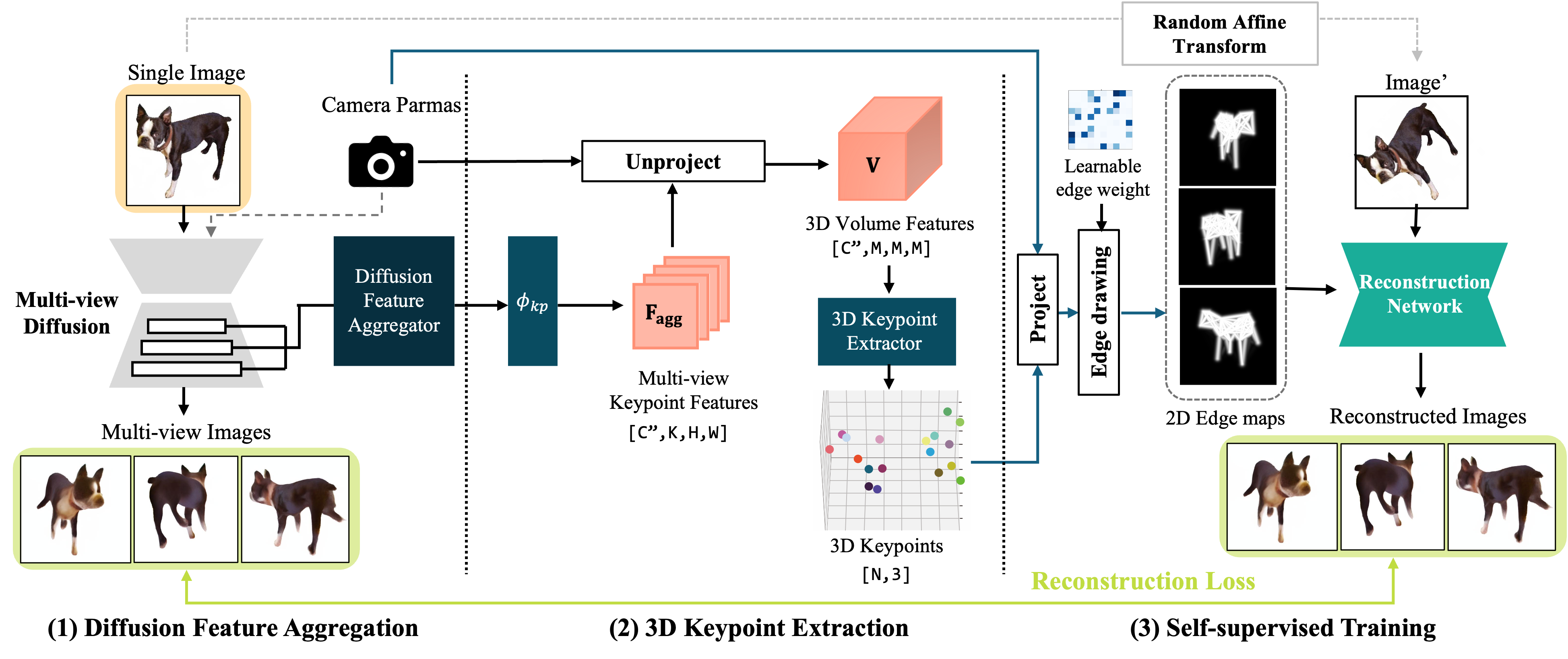
Figure 2. The overall pipeline of KeyDiff3D.
Our method outperforms all unsupervised single-view baselines and achieves competitive results with multi-view baselines using only a single-view image. It also achieves improved P-MPJPE compared to monocular human pose estimation methods employing human-specific priors.
Figure 3. Qualitative comparison on the Human3.6M dataset.
We train our model on diverse animal categories using CUB-200-2011 and Stanford Dogs — both consist of single images captured in natural environments, without multi-view or 3D annotations. Our method reliably captures semantic parts and 3D structure under varied poses, articulations, and occlusions.
CUB-200-2011
Stanford Dogs
Figure 4. Qualitative results on CUB-200-2011 and Stanford Dogs.
Although trained only on indoor Human3.6M (five subjects) or Stanford Dogs, our model generalizes well to in-the-wild DAVIS images and AP-10K animal species — including rhinoceroses, zebras, and giraffes. Despite the large variations in shape, appearance, and limb structure, our method consistently predicts semantically meaningful keypoints.

Human3.6M (train) → DAVIS (test)

Stanford Dogs (train) → AP-10K (test)
Figure 5. Cross-domain generalization. Models trained on Human3.6M and Stanford Dogs generalize to in-the-wild DAVIS videos and AP-10K animal species.
Our predicted 3D keypoints are aligned with the coordinate system of the diffusion model and the generated multi-view images. Combined with Gaussian Frosting reconstructions, this enables articulation and deformation of generated 3D objects without requiring object-specific skeleton design or manual rigging.
Figure 6. Animatable 3D model results.
3D keypoint accuracy on Human3.6M. Lower is better. * denotes results on a simplified subset with six actions.
| Setting | Method | #Views | #KP | Regression | MPJPE ↓ | N-MPJPE ↓ | P-MPJPE ↓ |
|---|---|---|---|---|---|---|---|
| Human Pose | Sosa et al. | 1 | 18 | - | - | - | 96.4 |
| Kundu et al. | 1 | 18 | - | 99.2 | - | - | |
| Kundu et al. | 1 | 18 | - | - | - | 89.4 | |
| Yang et al. * | 4 | 18 | - | 85.6 | 85.6 | 79.3 | |
| Multi-View | BKinD-3D | 4 | 15 | Linear | 125 | - | 105 |
| BKinD-3D | 2 | 15 | Linear | 155 | - | 117 | |
| Honari et al. | 4 | 32 | 2 hid MLP | 73.8 | 72.6 | 63.0 | |
| Single-View | Keypoint-net | 1 | 32 | 2 hid MLP | 158.7 | 156.8 | 112.9 |
| Honari et al. | 1 | 32 | 2 hid MLP | 125.73 | 121.04 | 89.05 | |
| Ours | KeyDiff3D | 1 | 18 | Linear | 130.58 | 127.69 | 96.83 |
| KeyDiff3D | 1 | 18 | 2 hid MLP | 121.34 | 118.29 | 85.26 | |
| KeyDiff3D | 1 | 32 | Linear | 127.41 | 124.93 | 96.18 | |
| KeyDiff3D | 1 | 32 | 2 hid MLP | 119.07 | 116.02 | 85.37 | |
| Ours * | KeyDiff3D * | 1 | 18 | Linear | 102.39 | 100.60 | 80.16 |
| KeyDiff3D * | 1 | 18 | 2 hid MLP | 85.47 | 84.38 | 66.73 |
Table 1. Quantitative comparison of 3D keypoint estimation on Human3.6M.
@inproceedings{jeon2026keydiff3d,
title = {KeyDiff3D: Unsupervised Monocular 3D Keypoint Discovery from Multi-View Diffusion Priors},
author = {Jeon, Subin and Cho, In and Hong, Junyoung and Cho, Woong Oh and Kim, Seon Joo},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2026}
}This work was supported by Institute of Information & communications Technology Planning & Evaluation (IITP) grant funded by the Korea government (MSIT) (No.RS-2022-II220124, No. RS-2024-00457882), and Artificial Intelligence Graduate School Program grant funded by Yonsei University (RS-2020-II201361).